Sistemi Operativi - Lezione in semi-presenza
Lezione in semi-presenza
4. Macchine Virtuali: moltiplicazione delle risorse
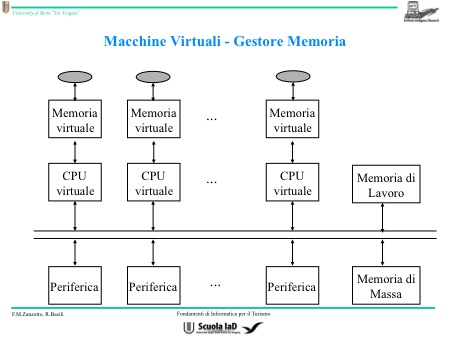

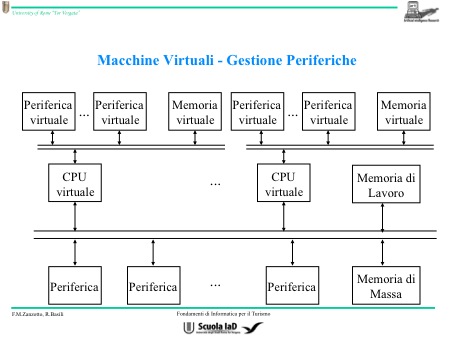
SCHEMA:
NUCLEO PROCESSO il programma (algoritmo nella fase di esecuzione)
CPU Virtuale (si appoggia su quella reale, fisica. Se ogni programma dovesse avere una propria CPU, il computer potrebbe eseguire un programma alla volta.)
MEMORIA Virtuale
Moltiplicazione della CPU




IL TUTTO PERCHE' OGNI PROGRAMMA CHE DIVENTA PROCESSO CREDE DI AVERE A DISPOSIZIONE UN PROCESSORE TUTTO SUO (cioè una CPU e Memoria sua), si ottiene una moltiplicazione delle risorse dei processori. Parto da un unico processore per più programmi, moltiplico le macchine in virtuali, dividendo in parti temporali, ogni utilizzatore crederà di essere l'unico ad usare la CPU. Se dividiamo la risorsa in 10 parti, avremo 10 processori quindi riusciamo a far eseguire più programmi al computer, ma ci rimette in velocità, perché un processore diviso in 10 sarà più lento. Ottengo macchine più lente, pur guadagnando in funzioni. Quindi per “moltiplicare il processore” divido il tempo per tutte le applicazioni, e assegno a ognuna un tempo per l’utilizzo della CPU che, di fatto, resta una sola. Esempio sulla maggior parte dei cellulari non è possibile eseguire più di un’applicazione alla volta; per poterne eseguire un’altra bisogna prima di tornare al menù principale.






Se S.O. è una collezione di programmi, con quale criterio un programma rilascia o riprende il controllo o possesso della CPU? Si è detto che per eseguire più programmi contemporaneamente- Multitasking , si divide il tempo della CPU, ma questo tempo deve essere assegnato, perciò occorre qualcuno che lo assegni. Il ruolo di assegnare il tempo è regolato da un evento esterno un’interruption- interruzione del programma, simile ad un timer che non è un clock, e ripristina il S.O., cioè il programma principe, che, se in quel momento deve fare qualcosa, la esegue, altrimenti restituisce il controllo al programma che stava lavorando prima dell’interruzione. Qualora il S.O. cede il controllo della CPU non esiste più come tale. Inoltre, se abbiamo una fila di processi che devono tutti essere eseguiti, quale si farà per primo eseguire? Qualcuno deve “ gestire la fila”. Il processo di decisione viene chiamato scheduling.
Il PROGRAMMMA è la traduzione dell'algoritmo in linguaggio macchina, adatto alla CPU. Quando un programma viene eseguito, in un certo senso lo stato della CPU si modifica, cioè occupa uno spazio nella memoria focalizzato e finalizzato, modificando i registri della CPU. Nel caso particolare, un programma occupa un registro specifico, cioè il Program Counter, che contiene l'istruzione successiva che dovrà esser eseguita. L’istruzione suddetta viene caricata dall’Instruction Register, e la macchina eseguirà ciò che è scritto nell’istruzione che è l’istruzione propria del programma. Essa sita nel Program Counter riguarda un programma, il quale non cederà la CPU ad un altro programma fin tanto che non avrà finito di eseguire l’istruzione o le istruzioni che lo riguardano. Sarà sua cura decidere quando rilasciarla. Di sicuro la rilascerà quando sarà giunto all’istruzione “halt”, e sarà sua discrezione decidere se rilasciarla prima. Il S.O.è un programma e segue anche lui questo procedimento: mette e toglie programmi dalla CPU.
Invece un programma che viene interrotto, viene per lo più messo in pausa- attesa e deve venir ripreso dal punto in cui è stato interrotto. La stessa cosa accade nei libri in cui, per riprendere da quel punto, si mette un segnalibro o si fa un’orecchia alla pagina, per definire lo stato di memoria in quel momento rispetto al libro, indica dove si è arrivati nell’assimilare quel libro, e cioè, in che punto si deve riprendere per assimilare il resto. Dopo un determinato periodo di tempo verrà ripreso dal principio poiché ci si ricorderà poco o nulla. Anche nel computer ci sono i segnalibri, ed il vero segnalibro al suo interno è il Program Counter perché ci ricorda dove si è arrivati nell’esecuzione del programma. Il segnalibro di un programma che era stato messo in stato d’attesa, si dovrà, per prima cosa ricordare lo stato del processo, a che punto si era arrivati e ciò viene fatto attraverso il Program counter. Lo stato del processo è: “ qual è la prossima istruzione da eseguire”, “ quali sono i propri dati che dovrebbero trovarsi in memoria”, cioè cosa si è già appreso e cosa si è già fatto. Un processo sequenziale può essere: ATTIVO, cioè mentre le istruzioni del suo programma vengono eseguite, quindi è nella CPU; IN ATTESA, cioè mentre attende di essere attivato; in stato di PRONTO, cioè quando attende di essere eseguito ad un processore. Dallo stato di PRONTO si può passare allo stato di ATTIVO, viceversa, dallo stato di ATTIVO si può passare allo stato di PRONTO. Se si lancia un qualche cosa che ha una durata di tempo ampia, dallo stato di ATTIVO si può passare dallo stato IN ATTESA. Quando la durata è ampia, non si può riprendere la CPU, ma si andrà a finire nello stato di PRONTO. Il posto dove mettiamo il segnalibro, si chiama Process Control Block- PCB, o Blocco di Controllo dei processi (insieme di informazioni a corredo). Esso contiene informazioni riguardo allo stato del programma, del Program Counter, dei Registri della CPU, è il segnalibro, il parcheggio. Il Process Control Block è molto importante perché ci può dire a che punto è arrivato il processo. In metafora, sarebbe l’insieme di pagine che si trovano prima del segnalibro nel libro che stiamo studiando o leggendo. Il suo elemento-principe è il Program Counter. Se perdiamo il segnalibro dal nostro libro, il tempo che impiegheremo per ritrovare l’informazione, sarà diverso dal tempo impiegato per ritrovare l’informazione nel libro con il segnalibro inserito. Quest’attività si chiama di “ ripristino dello stato”. Se il tempo di ripristino dello stato è piccolo, il vantaggio c’è, ma se il tempo è maggiore dello svolgimento stesso del programma non ha senso il ripristino. Nel caso ci siano molte cose da fare e si perde quindi tempo a ripristinare lo stato si chiama Trashing (buttare via il tempo). Un processo ha informazioni a corredo che vanno caricate e scaricate, qualora ciò necessiti troppo tempo non vale la pena. Ci deve essere un processo che faccia in modo che l’intero processo sia efficace. Ma come e perché scelgo un processo rispetto ad un'altro? SCHEDULING esegue un processo fin quando non può più evolvere o fin quando si decide essere utile, lo decide il S.O. Si verifica lo sta del processo in corso e si sceglie quale possa essere il più utile con lo scopo di ottenere il miglior risultato con il miglior danno su tutti i processi. Con lo scopo globale del sistema di riuscire a far in modo che i processi funzionino tutti allo stesso modo.
Sistemi operativi sono molto importanti poiché gli utenti non possono parlare direttamente con la macchina attraverso impulsi elettrici (così sono rappresentate le informazioni nella macchina), ma dobbiamo parlarci tramite un linguaggio a noi vicino. Tale linguaggio, in qualche modo, deve venir comunicato alla macchina. Il computer non svolge un solo programma alla volta, come fa? Ad esempio, La macchina astratta ci deve garantire di poter comunicare con i dispositivi reali (sottostanti) attraverso linguaggi a noi sempre più vicini. Il sistema operativo è costruito a strati e questi strati sono astrazioni sempre maggiori della macchina stessa. Il primo elemento (il più interno) è il nucleo. Il nucleo ci da la prima astrazione, una volta ricevuta la prima astrazione, si può gestire la memoria, poi la seconda astrazione… per dare, in fine, un’interprete dei comandi. Il primo salto è quello che ci serve per far lavorare i programmi semi-contemporaneamente. Quindi il nucleo Per funzionare, il programma ha bisogno di una CPU, ma non è possibile che ogni programma abbia una sua CPU, perciò si appoggia solamente su quella reale. Infatti, L’operazione di partizionare/dividere il tempo consiste nel dividere la risorsa in diverse parti temporali, in ogni parte vale un processore per un certo periodo di tempo. Lo strato più interno, è il nucleo che Il nucleo si trova immediatamente sopra la macchina fisica (in figura HW) che sarebbe la CPU e viene realizzata attraverso l’architettura di Von Neumann. Questa macchina deve poter essere cambiata per usare un calcolatore, un cellulare o una macchina che sia, come si vuole. Perciò, la prima cosa da fare nel nucleo, è far credere a ciascun programma che viene eseguito, di avere una CPU a propria disposizione, cosa che non si potrebbe mai verificare, soprattutto quando più applicazioni vengono eseguite nello stesso momento, perciò non si tratta di un’operazione semplice. Importante è anche il ruolo delle macchine astratte che fanno credere ai programmi di disporre della CPU per un lungo tempo, come se, di fatto, ogni applicazione avesse una CPU per sé. Ma si è visto che ciò non è possibile e quindi si divide il tempo d’uso dell’unica CPU per tutte le applicazioni. Quando un programma è in esecuzione, ciò che accade è che tale programma occuperà spazio in memoria. Ma occuperà quello spazio di memoria adibito a particolari attività, e cioè i Registri della CPU. .E’ il Program Counter, infatti che dice qual è la istruzione successiva . se Il Sistema operativo è un programma che ha lo scopo di fornire una modalità di togliere e mettere programmi nella CPU di modo che possa suddividere il suo tempo in tanti “ segmenti”, quindi, quando nel Program counter viene messa un’istruzione di un altro programma, verrà eseguito dalla CPU quel programma e il Sistema Operativo non ha più il controllo. Come fa a riprenderselo?
L’attività di ripristino dello stato ha un costo in termini di tempo. Se il tempo impiegato per tale attività è maggiore della quantità di tempo che abbiamo a disposizione, o che viene concessa al processo per fare qualche cosa, allora non vale la pena farlo. Avendo un processo che si sta eseguendo nella CPU, lo si esegue fin tanto che non è troppo lungo, o fin tanto che non si decide qual è l’altro processo che vogliamo eseguire. Dati due processi, il processo P e il processo Q, se si decidesse di eseguirli uno di seguito all’altro, l’esecuzione finale si otterrebbe. Un processo comincia a dirsi soddisfatto nel momento in cui comincia ad essere eseguito.
Il concetto di macchina astratta aiuta ad introdurre quello di Sistema Operativo perché il Sistema operativo ha come obiettivo principale quello di rendere simili macchine differenti: costruisce macchine astratte simili su macchine reali differenti.
Data una macchina astratta, la si vuole usare con più programmi contemporaneamente. Si è dovuto introdurre il concetto di “ moltiplicazione delle risorse”, perché ogni programma deve poter avere la macchina così com’era, a sua disposizione.
Su una macchina astratta vivono tanti programmi detti processi i quali sono tutti indipendenti. È proprio la loro indipendenza che crea un problema, poiché devono condividere le risorse (la CPU).
Come fa il sistema operativo a decidere chi ha diritto, in un determinato momento, alla risorsa (che può essere la CPU o la Memoria)?
E, una volta “ servito” un programma, quale sarà il programma successivo della coda ad essere “ servito”?


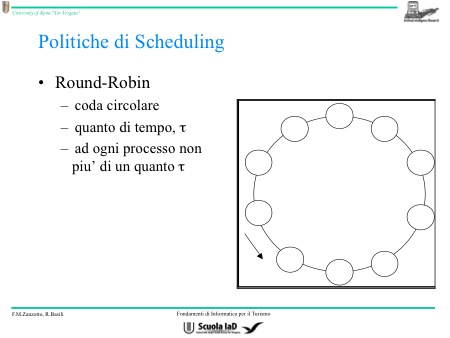
Le politiche per gestirlo sono quelle che ci vengono più naturali, le quali poi si trasformano in algoritmi. Così abbiamo l’algoritmo FIFO, l’algoritmo Shortest-Job-First (compito meno oneroso), algoritmo basato sulla priorità e l’algoritmo Round-Robin.
- First in-first out (FIFO): principio della fila, il primo che entra sarà il primo ad uscire.
- Last in-first out (LIFO): anche detto first in-last out, il primo ad entrare sarà l'ultimo ad uscire.
- Shortest job first: terza politica, chi ha meno lavoro da fare ha la precedenza sugli altri. Questo principio non può venire applicato all’infinito.
- Principio basato sulla priorità: a lavori diversi corrispondono file diverse. Se io appartengo ad una classe, vengo servita per prima.
- Round-Robin: è il più utilizzato. Ogni programma fa un pezzetto alla volta, così si fa credere a tutti di procedere contemporaneamente.
L’algoritmo più utilizzato, è il Round-Robin che, in un certo senso, potrebbe usare come scelta tutti i precedenti. Si tratta di un algoritmo che fa credere ai programmi di progredire tutti contemporaneamente.
Per comprendere meglio quest’algoritmo, facciamo l’esempio del bar: la situazione del bar è particolare poiché la coda è quella che si fa per pagare alla cassa, ma il momento del bancone non è propriamente una coda in quanto tutti i clienti sono allineati su una stessa linea orizzontale. Può crearsi anche più di una linea orizzontale, in ogni caso, sembra che gli appartenenti ad una stessa linea, siano serviti tutti nello stesso momento. In realtà non è così, ma piuttosto i baristi, in questo caso, dividono “ l’attività complessa” in tanti sotto-passi.
Il primo sotto-passo è quello di osservare chi ha la necessità di essere servito nella prima linea, l’individuo che deve essere servito da lo scontrino e il barista mette davanti a lui il piattino, quest’azione la fa per tutti coloro che si trovano nella prima linea. Il piattino sarebbe il Program Counter. In questo primo momento, si è serviti in sequenza, ma in un certo senso contemporaneamente. Il secondo passo prevede che qualche cosa venga messo sul piattino (la tazza). Il terzo passo è stabilire il tempo, perché se c’è una fila, la persona non potrà rimanere ore con la tazza davanti al bancone.
Quando si libera un posto, viene servita un’altra persona: è una sorta di coda circolare, ma in questa coda circolare si da un tempo ad ognuno. Ad ogni persona non si può dare più di un tempo “T”.
Quindi sembra che nel Round-Robin tutti i programmi evolvano insieme ed inoltre sembra che vadano anche più velocemente. A ciascun programma viene dato un tempo (tau) uguale. Quando il tempo scade, la CPU gli viene tolta.

Dati tre processi, P1, P2 e P3, sappiamo che P1 impiega 24 millisecondi, P2 ne impiega 3 e P3 ne impiega anch’esso 3. P2 dovrà attendere, perciò, 24 millisecondi, ma P3 ne dovrà attendere 27 (il tempo d’attesa è lungo). Se dessimo a ogni processo 4ms (tempo che un processo attende per fare qualche cosa e non per completarsi) vedremo che P1 deve attendere 0ms, P2 deve attendere 4 ms (anche se ne impiega 3 per fare la cosa) e P3 attende 7 ms (il tempo d’attesa è piccolo e quindi fare il Round-Robin è vantaggioso).
Il Round-Robin è diverso dalle altre politiche/altri algoritmi; le altre politiche che ho a disposizione si usano per fare la “coda”, ma il resto è un procedimento circolare che prende il nome di Round-Robin.
Tutti questi modelli possono tradurre in algoritmi!!