Architettura del Calcolatore - Lezione in semi-presenza
| Site: | Università di Tor Vergata for UNWTO |
| Course: | Fondamenti di informatica per il turismo |
| Book: | Architettura del Calcolatore - Lezione in semi-presenza |
| Printed by: | Guest user |
| Date: | Wednesday, 1 July 2026, 10:04 PM |
Description
Lezione in semi-presenza
1. Introduzione
Nella parte di rappresentazione dell’informazione, ci siamo interessati di cosa rappresentare voglia dire. Abbiamo scoperto che le cose possiamo chiamarle come vogliamo perché è solo una convenzione se si chiamano in questo modo. Ma la rappresentazione del linguaggio storico-naturale presenta un problema che è quello dell’ambiguità, mentre quello della ricchezza espressiva è un “ arricchimento”.
Una volta stabilito cosa vogliamo rappresentare (istruzioni e dati), abbiamo risolto il nostro problema: abbiamo scelto di rappresentare il tutto attraverso una rappresentazione simbolica e per questo useremo i numeri e, abbiamo capito che per i numeri possiamo scegliere la base. Base che può essere anche binaria in quanto c’è garanzia che tutto funzioni.
Altro argomento: L’ARCHITETTURA DI UN CALCOLATORE
Abbiamo messo in cantiere il concetto di algoritmo e anche il concetto di rappresentazione, dopo aver visto come l’algoritmo poteva venir rappresentato. Però ancora non abbiamo un qualcosa per elaborare questi algoritmi.
Se scriviamo bene i nostri numeri (posizionali ad esempio), possiamo avere algoritmi efficienti. La stessa cosa la dobbiamo fare per tutti gli algoritmi.
2. Idee fondamentali per costruire macchine universali



Il problema ora è avere qualche cosa che elabori e poi risolva questi algoritmi.
Ci occorre un esecutore generale di tutti gli algoritmi. L’uomo è un esecutore generale di tutti gli algoritmi?
Sicuramente non è in grado di risolvere ogni algoritmo, ma alcuni li sa risolvere: eseguire una ricetta, fare una somma… quindi può venir considerato un esecutore generale di algoritmi. L’uomo risolve l’algoritmo se gli è possibile e se ne ha voglia.
Ma come fa l’uomo per risolvere questi algoritmi? Ha una strategia? Ad esempio, come facciamo a leggere?
Vediamo una serie di caratteri e li interpretiamo, poi li mettiamo insieme in un’unica parola che è generalmente delimitata da spazi bianchi, e poi leggiamo le righe, le pagine… quella di leggere da sinistra verso destra e di fare una micro pausa finita ogni parola, è una cosa che ci è stata insegnata quando abbiamo imparato a leggere.
Identica procedura che facciamo per leggere, si fa anche per risolvere un algoritmo: leggiamo la prima istruzione, la comprendiamo e poi la risolviamo, poi lo stesso procedimento per la seconda e per la terza, fino ad arrivare alla soluzione.
Esistono due idee fondamentali:
L’algoritmo vitale che è un algoritmo capace di eseguire gli altri algoritmi e fa 4 operazioni in sequenza: localizzazione, lettura, decodifica ed esecuzione.
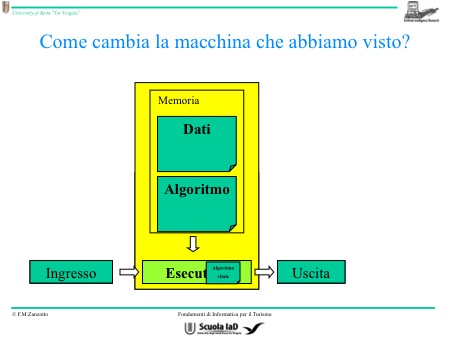
Da un certo punto di vista, dati e algoritmi sono la stessa cosa perché gli algoritmi possono diventare dati per un altro algoritmo. Nel caso particolare, tutti gli algoritmi che “ mettiamo in campo” sono dei dati per l’algoritmo che esegue gli altri algoritmi. Perciò, dati e algoritmi li possiamo rappresentare allo stesso modo.
Non basta dire che ci sono dei dati iniziali in un algoritmo, in quanto vi sono anche dei dati che variano al procedere. Dati che non saranno presenti nel risultato finale, ma che porteranno a esso. Questi dati sono ad esempio i riporti, si tratta di dati interni all’algoritmo che non sono né i dati iniziali né il dato finale (il risultato).
La possibilità di poter mettere insieme dati e algoritmi, ci fa arrivare a dire che stanno nello stesso spazio, e questo spazio è chiamato memoria. I dati in ingresso si chiamano sempre dati in ingresso, ma il risultato prende il nome di dato (o dati) in uscita. L’algoritmo vitale, ovvero l’algoritmo che deve risolvere tutti gli altri algoritmi, non può trovarsi nella memoria insieme agli altri algoritmi.
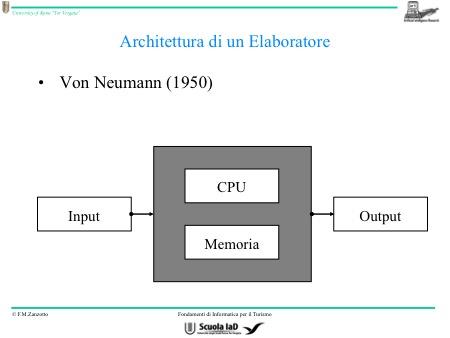
Deve essere, piuttosto, patrimonio dell’esecutore, quest’algoritmo è nella CPU. Questa è la macchina di Von Neumann. L’esecutore nella macchina di Von Neumann è detto appunto central processing unit (CPU). Potremmo meglio dire che l’algoritmo privilegiato è il ciclo operativo che fa funzionare la CPU e che le insegna a risolvere gli altri algoritmi contenuti nella memoria.
E’ come se avessimo un cervello diviso in due parti: sinistra e destra. Ma queste due parti prima o poi dovranno comunicare. Si tratta di un approccio molto simile alla visione funzionalistica del cervello.
Alle macchine funzionali (come quella di Von Neumann) si contrappongono le macchine neuronali (formate da tutte unità simili), all’epoca c’era la possibilità di costruire un prototipo di entrambe, ma l’architettura dei calcolatori è basata sulla macchina di Von Neumann. Ma perché si è scelta l’ipotesi funzionalista?
Perché era più facile da controllare, inoltre, nell’altra ipotesi, non si riusciva bene a capire dove mettere l’elemento di controllo.
3. La Memoria














Come si fanno a trovare facilmente le informazioni che vogliamo consultare sulla memoria?
Le informazioni si possono trovare facilmente nella memoria poiché si tratta di uno spazio organizzato. Così come anche il libro è uno spazio organizzato in pagine le quali sono numerate.
Vi sono due modi per risalire all’informazione: cercarla per contenuto o sfruttare una proprietà dello spazio dove tale informazione è contenuta.
La memoria è suddivisa in tanti spazi tutti uguali. Questi spazi prendono il nome di cella. Ogni cella è individuata da un proprio indirizzo che fa in modo che si possa risalire all’informazione in essa contenuta rapidamente. Una cella contiene una data somma d’informazioni e non ne può contenere né di più né di meno. Al limite sarà una cella vuota, senza informazioni (per il momento).
Per scrivere o prelevare delle informazioni che ci servono, non possiamo andare direttamente nella memoria a prelevarle, ma dobbiamo interagire con una parte. Nel caso del calcolatore, dobbiamo interagire con una tastiera. Perché, appunto, ognuna di queste celle ha anche un nome. Nome che ci permette di raggiungere lo spazietto.
La memoria utilizzabile è uno spazio definito, diviso in parti uguali (partizionato), le cui parti hanno un nome e cioè un indirizzo.
Più precisamente, la memoria è uno spazio partizionato e indirizzabile in cui è possibile mettere e reperire le informazioni utilizzando il nome dello spazietto (detto indirizzo).
Vogliamo capire com’è fatta l’architettura di un calcolatore. Le cose fondamentali da sapere sono due: esiste un algoritmo vitale (ciclo operativo) che permette l’esecuzione degli altri algoritmi e poi la confusione tra dati e algoritmi (i quali possono stare nello stesso spazietto). I dati e gli algoritmi si trovano nella memoria che è strutturata in un modo particolare.
Queste due idee fondamentali, danno vita alla macchina di Von Neumann, o architettura di Von Neumann che è solo una delle possibili architetture di un calcolatore pensata a quei tempi, ma che poi, di fatto fu adottata per tutti i computer.
Funzionalmente, quest’architettura è divisa in due parti, ognuna di queste due parti si occupa di una specifica attività. La prima attività, svolta dalla memoria, è memorizzare, mentre la seconda attività, svolta dalla CPU, è fare qualche cosa. L’algoritmo vitale si trova nella CPU.
La memoria è strutturata in un modo preciso affinché possa essere utilizzabile. Ma com’è organizzata la memoria centrale? (tutte le altre memorie sono organizzate ugualmente).
La memoria “ utilizzabile” è uno spazio suddiviso in parti uguali, ognuna di queste parti ha un suo proprio nome che è l’indirizzo, e in ognuna di queste parti è possibile mettere un solo elemento informativo. Quest’elemento informativo può essere scritto o non-scritto perché ogni cella della memoria può essere riempita o vuota, ma non può essere riempita più di ciò che può contenere.
Perciò una caratteristica fondamentale di questo spazio è la sua finitezza, si tratta di uno spazio finito, dove non posso mettere i valori che voglio. Posso farlo fino a che non raggiungo il numero massimo consentito dallo spazio.
Le celle in cui la memoria è divisa sono tutte uguali. L’indirizzo, quindi il nome di ogni cella di memoria, può variare da N a N – 1, là dove N è il numero di celle in cui la memoria è suddivisa.
Il valore che si trova dentro ogni spazietto della memoria, è il valore che vogliamo memorizzare. Questo valore sarà un numero, si scelgono proprio i numeri come valori da metterci perché tutto è numerabile e tutto si può rappresentare attraverso i numeri. Quei numeri non sono numeri qualsiasi, ma sono numeri binari.
Perché è vero che tutto è rappresentabile attraverso i numeri, ma si sceglie una rappresentazione unica, la più semplice che è proprio la numerazione binaria. È una rappresentazione semplice perché è molto facile costruire degli elementi a due stati, cioè i transistor. Quindi, la scelta della rappresentazione binaria è un altro accidente storico, perché si è scelta esclusivamente per il fatto che costruire elementi con due stati è semplice.
Sarebbe stata più semplice la rappresentazione a uno stato solo, ma con la rappresentazione a uno stato non si può rappresentare l’informazione.
Appurato che la rappresentazione è quella binaria, in ogni spazietto non può trovarsi più di una cifra binaria. Questo spazietto binario prende il nome di bit. Il bit può assumere valori 0 e 1.
La sequenza di bit, cioè ciò che rappresenta tutti gli spazi in cui è divisa la memoria, prende il nome di parola o parole.
La nozione di parola in informatica non è da confondere con la nozione di parola “ standard”. La nozione di parola, in informatica, indica una sequenza di bit limitata e ben definita. Il numero di bit si indica con N.
Il bit è lo spazio che può assumere valore 0 o 1 e che rappresenta, cioè, l’unità informativa minima, è il nome dello spazietto che c’è già prima di essere riempito da uno 0 o da un 1.
Esistono delle parole che hanno preso un valore più significativo delle altre, distinguendosi. Queste vengono chiamate byte. I byte sono parole formate da 8 lettere (8 bit).
Avendo un byte, quindi una parola di 8 bit, quanti valori posso rappresentare?
Avere Windows a 32 o 64 bit significa dire quante parole posso rappresentare, e ciò ha una grandissima importanza nella memoria gestibile dal computer perché gli indirizzi hanno la stessa lunghezza della parola.
Se hanno lunghezza pari a un solo byte, saranno poche le celle di memoria indirizzabili, mentre saranno molte se hanno lunghezza 32 o64 bit. Avere un computer a 32 o 64 bit sta ad indicare la massima estensione della RAM (random access memory).
4. Comunicazione tra CPU e Memoria





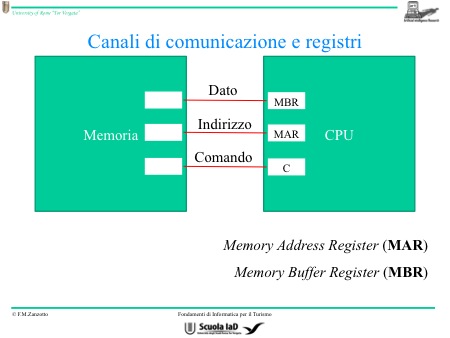


Per comunicare con la CPU, analogamente come faremmo se volessimo comunicare con un distributore di bibite e merendine, dobbiamo usare degli specifici canali di comunicazione. C’è una procedura determinata per trattare con la CPU. Sappiamo che nella memoria possiamo scrivere o leggere delle informazioni.
Nell’operazione di lettura c’è un qualche cosa (un’informazione) che dalla memoria dovrebbe andare a finire nella CPU e viceversa per la lettura. Quindi la memoria deve comunicare con la CPU.
Le modalità di interazione con la memoria avvengono solo per le operazioni di lettura e scrittura, non sono infinite. Per parlare alla memoria occorre uno specifico linguaggio, ma quali e quanti sono i canali attraverso i quali si parla con la CPU?
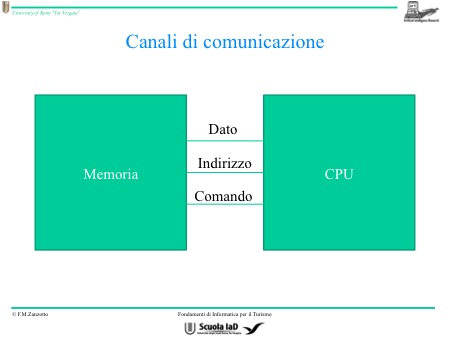
Per prima cosa bisogna comunicare alla memoria l’indirizzo che dovrà passare attraverso un canale di comunicazione. Dopo di che c’è il dato che è ciò che vogliamo far passare dalla CPU alla memoria o dalla memoria alla CPU. È il dato che vogliamo scrivere nella memoria, o leggere.
Occorrono quindi due canali di comunicazione con la memoria e un terzo che è il controllo. Questi tre canali sono chiamati anche Bus perché Bus è sinonimo di canale.
Questi tre canali di comunicazione (Bus), quindi, sono:
- quello dei dati;
- quello degli indirizzi;
- quello di controllo (in quest’ultimo passa l’istruzione).
Sappiamo che l’indirizzo ha la lunghezza di una parola, ma anche il dato è una parola perché sono lunghi uguali. Mentre il canale di controllo è più breve, basta un solo bit per codificare le operazioni, e quindi un solo canale di comunicazione.
Nella lettura, la CPU mette a disposizione solo l’indirizzo e indietro si riceverà il dato contenuto nella cella che ha come nome quell’indirizzo. Nella scrittura, invece, la CPU mette a disposizione l’indirizzo e il contenuto, cioè il dato che si vuole scrivere nella cella rappresentata da quell’indirizzo.
Lettura: informazione dalla memoria alla CPU.
Scrittura: informazione dalla CPU alla memoria.
Ma dove vanno a finire queste informazioni?
La CPU ha dei posti dove queste informazioni finiscono preventivamente per poi trasmetterle o ricevere ancora informazioni che vengono dalla memoria stessa.
Osserviamo che, anche all’interno della CPU, infatti, esistono degli spazietti di memoria che sono chiamati registri. Si tratta di spazi di memoria molto diversi dalle celle della memoria, perché, al contrario di questi, i registri non sono spazietti indistinti, ma ognuno ha una sua propria funzione.
Per comunicare con la memoria, ne servono tre di registri:
- il registro dell’indirizzo di memoria, Memory Address Register (MAR);
- il registro del contenuto di memoria, Memory Buffer Register (MBR);
- il registro del comando (C).
Questi sono i terminali dei tre canali di comunicazione che la CPU ha con la memoria.
M(MAR) MBR. Dove M è la memoria. Questa scrittura serve a descrivere, sintetizzando, le operazioni di lettura e scrittura. La formula è la stessa, soltanto cambia la direzione della freccia che, nella formula di scrittura ha la punta verso (MAR), mentre nella formula dell’operazione di lettura la punta della freccia è rivolta verso MBR.
Perché, nella scrittura, il contenuto che si trova nel Memory Buffer Register, va a finire nella celletta di memoria M(MAR). Nell’operazione di lettura, invece, il contenuto della cella di memoria M (MAR) va a finire nel Memory Buffer Register.
Nella gerarchia della memoria, esistono differenti tipi di memoria: i registri (specializzati) che sono all’interno della CPU, la Memoria centrale o Random Access Memory (RAM), Memoria secondaria, Memoria Cache.
RAM vuol dire memoria ad accesso casuale che si oppone alle memorie con accesso sequenziale (le video cassette, le audio cassette…). Memoria ad accesso casuale significa poter scegliere dove andare, la canzone da ascoltare, il dato da leggere, … senza rispettare la sequenza.
Le Memorie secondarie sono gli Hard Disk, le Pen-drive… le Pen-drive, hanno la stessa organizzazione della memoria centrale, ma sono virtualmente usati come gli Hard Disk. Anche gli Hard Disk sono divisi in parti, non uguali, che sono chiamati settori, e che hanno conformazione diversa rispetto alle celle della memoria.
La Memoria Cache è una parte di memoria che si trova tra i registri e la RAM. È una memoria molto vicina alla CPU il cui accesso è molto rapido, è più piccola della memoria centrale e serve per svolgere le operazioni ripetitive e di riporto dei bit (Carry). E’ indifferenziata come la Memoria centrale, quindi, pur essendo vicino alla CPU, la Cache non è “ specializzata”.
5. L'unità centrale di processamento (Central Processing Unit, CPU)









Nella CPU c’è il ciclo operativo o algoritmo vitale che ha il compito di eseguire gli altri algoritmi, ma come fa?
Nella CPU c'è:
- il registro IR (grande 2 parole)
- i registri degli operandi (ogni operazione è codificata da soli 2 bit)
- ALU (la capacità di fare le operazioni)
- la capacità di estrarre dalla memoria qualcosa
5.1. Algoritmo vitale (o ciclo operativo) e i suoi registri
Ma anche il ciclo operativo è un algoritmo, ma è più importante degli altri, infatti è l’algoritmo vitale. In quanto algoritmo, però, è costituito da una sequenza di istruzioni. Se l’istruzione che vogliamo eseguire si trova nella memoria, bisognerà per prima cosa localizzare quest’istruzione, poi bisognerà Caricarla, Decodificarla ed infine Eseguirla.
Le operazioni che deve fare il ciclo operativo sono quindi quattro. La decodifica e l’esecuzione sono le due operazioni più importanti.
Fino a quando l’istruzione è diversa da “halt”, l’algoritmo continua con queste quattro operazioni.
La volta scorsa si è detto che esistono due registri: il Program Counter (PC) e l’Instruction register (IR). Il Program Counter è il registro in cui in ogni momento è memorizzato l’indirizzo della prossima istruzione, mentre l’Instruction Register è il registro che contiene l’istruzione in fase di esecuzione.
5.2. Linguaggi della Macchina: Codificare le istruzioni






La CPU funziona con un linguaggio non ambiguo.
Come codifichiamo le istruzioni? Con i numeri binari.
Quanti bit servono per codificare un carattere? 8 bit.
Codice ASCII per codificare i caratteri.
Come si possono codificare le istruzioni che inseriremo nell’Instruction Register?
Non ci serve sapere cosa inserire nel Program Counter, poiché già sappiamo cosa c’è e sappiamo anche a cosa serve, ovvero serve affinché il ciclo operativo funzioni. Siccome nell’Instruction Register ci deve essere un’istruzione, bisogna imparare come eseguirla.
L’Instruction Register deve essere lungo almeno una parola perché contiene l’istruzione. Proprio perché si tratta di un’istruzione, è più semplice che sia lunga due parole. Questo perché così risulterà più semplice leggerla.
Ciò che occorre codificare sono le operazioni (somma, sottrazione, divisione…), e bisogna codificare tutte quelle istruzioni che sono tipiche degli algoritmi.
Le istruzioni degli algoritmi sono ben comprensibili sfruttando i diagrammi di flusso. Tramite i diagrammi di flusso si comprende che le istruzioni non sono tutte uguali perché hanno una diversa importanza. Ognuna di queste istruzioni ha un segno diverso. Perciò bisognerà trattare ogni istruzione in un diverso modo, comprendendo cos’è che bisogna calcolare.
Se un’istruzione contiene solo due parole, non se ne possono inserire di più. Perciò, istruzioni troppo lunghe non si possono codificare.
Per fare in modo che entrino anche le istruzioni originariamente troppo lunghe, dobbiamo pensare a un modo per codificarle, in modo che entrino nell’Instruction register.
Nei diagrammi di flusso, le istruzioni erano poche, ma con quelle poche si potevano rappresentare tutte le funzioni utili a scrivere gli algoritmi.
Le tipologie di istruzioni nei diagrammi di flusso erano le affermazioni (la somma…), i salti condizionati (in cui c’è una condizione), e il salto (che fondamentalmente è il flusso).
La prima istruzione che si analizzerà è l’Istruzione di assegnazione/modifica: che rappresenta così: Assegna ad A il valore 2 (scrittura in linguaggio naturale).
Non si può scrivere ciò dentro 32, 64 bit perché non centrerebbe, infatti sappiamo che un carattere è rappresentato da 8 bit, e già per quattro caratteri avremmo utilizzato una parola. Perciò occorre un modo più sintetico per descrivere la stessa cosa.
Si potrebbe usare la scrittura A = 2 oppure A 2.
Oltre all’Instruction Register, nella CPU ci sono anche altri registri (R1; R2…) che sono gli operatori, poi c’è l’ALU che consente di svolgere le operazioni, e poi c’è la capacità di estrapolare qualche cosa dalla memoria.
Se prendiamo A e B, questi possono essere Registri o Locazioni di memoria. Si è detto che in un’istruzione lo spazio a disposizione è poco, perciò, cosa possiamo permetterci di codificare?
Al massimo possiamo permetterci di codificare un indirizzo.
A e B sono delle locazioni di memoria e delle variabili. Se A e B sono entrambi spazi di memoria, devono avere entrambi un loro indirizzo. Una volta venuto a conoscenza degli indirizzi, posso copiare il contenuto di B nella locazione di memoria A, o viceversa.
Ma non posso codificarlo, perché se volessi codificare entrambi come spazi di memoria, avrei la necessità di scrivere sia il primo indirizzo sia il secondo indirizzo.
In questo modo, però, si occuperebbe tutto l’Instruction Register senza aver indicato l’operazione da fare. Perciò due indirizzi non possono convivere, perciò, se A e B sono entrambi indirizzi, quest’operazione non è possibile.
Le operazioni che invece è possibile scrivere sono quelle in cui l’operando (ciò che voglio inserire) è una costante e i destinatari non sono locazioni di memoria, ma sono registri interni.
Se infatti possiamo inserire nell’Instruction Register solo un indirizzo, l’altro prelevato si potrà inserire in un registro della memoria. Il numero dei registri non è alto e quindi ho bisogno di pochi bit: se i registri sono quattro, ho bisogno di soli due bit.
L’operazione di mettere insieme un indirizzo e un registro, la si può fare sia in uscita che in entrata.
L’operatore è la freccetta, mentre gli operatori sono A e 2. Gli operandi prendono nomi specifici, cioè sorgente e destinazione.
Uno dei due operandi è l’indirizzo, o una costante, mentre l’altro operando deve essere un registro, perché altrimenti lo spazio per mettere le informazioni non c’è. Generalmente l’operando 1 è un registro mentre l’operando 2 è un indirizzo. L’operazione di “ sposta” è segnalata dalla freccetta.
Nell’operando B, che è un indirizzo, non posso scrivere B + 1 (dove questa B è un indirizzo) perché sarebbe come scrivere un’operazione dentro un’operazione.
B + 1 deve diventare un’operazione che deve essere svolta precedentemente.

Spostare le informazioni tra due locazioni di memoria è possibile. E’ impossibile spostarle direttamente. Per farlo bisogna prima risolvere un problema.
Per scambiare A e B occorre trovare una posizione temporanea perché non si può immediatamente scambiare A con B poiché risulterà che B è già occupato.
Questo terzo elemento viene chiamato Temp e deriva dal significato dell’operazione “sposta”
Con questa tipologia di istruzione è possibile svolgere solo le operazioni che il processore è in grado di svolgere; si tratta di un altro vincolo.



La seconda tipologia di operazioni che si ha a disposizione sono Le operazioni di Salto. Si tratta di operazioni complicate da codificare in due spazietti.
C’è il SALTA SE; la CONDIZIONE; l’OPERANDO.
Se si verifica una data condizione si può operare, altrimenti no.
Quello che si sta definendo è un linguaggio che ha una specifica sintassi: è scritto in un determinato modo e segue delle regole. Inoltre, in questo linguaggio, il numero delle istruzioni è ridotto, e queste istruzioni hanno un effetto sulla macchina.
Effetto che è il significato delle istruzioni, la loro semantica.
Una volta passata l’istruzione nella macchina, qualche cosa avviene al suo interno. Un qualche cosa che in realtà è sempre la stessa cosa.
Tramite queste istruzioni si sta dicendo precisamente ciò che deve avvenire all’interno della macchina. Si deve notare, perciò, come il concetto di “ ambiguità” (che era scomodo) è stato eliminato.
Ogni macchina divisa in parti, come la macchina di Von Neumann, per funzionare devono avere un linguaggio ben specifico. Quando un qualsiasi utente usa una di queste macchine, utilizza il loro linguaggio.
La Macchina di Von Neumann è formata da una parte che esegue e da una parte che memorizza. Nessuna di queste due parti può funzionare indipendentemente dall’altra perché sono necessarie l’una all’altra.
Per fare funzionare la parte che esegue, ovvero la CPU, abbiamo bisogno di uno specifico linguaggio. Linguaggio che non deve essere ambiguo, e deve avere una sintassi particolare, perché bisogna accertarsi che faccia quello che l’utente gli dice di fare.
Le istruzioni sono di diverso tipo, ed hanno una loro classificazione:
- istruzione di assegnazione/modifica
- istruzione di salto e di controllo
- istruzioni di I/O
Vediamo un esempio per l’istruzione di controllo:
se (A “maggiore” B) allora il MASSIMO è A; altrimenti il MASSIMO è B
le istruzioni di condizione prevedono: una condizione; una modifica della sequenza delle istruzioni.
Il salto condizionato è composto da:
- frase lecita: SALTA-SE-“COND” “OPERANDO” (vedi slides).
La stessa versione del salto condizionato, in inglese, sarebbe JMP; JUMP era salta se “maggiore”. La scelta dell’italiano, dell’inglese o di altri simboli, è irrilevante, basta che ci si mette d’accordo.
Queste istruzioni si codificano tramite i numeri binari.
Parte di ciò che abbiamo a disposizione, ce lo giochiamo con l’indirizzo, mentre l’altra parte ce la giochiamo con il registro.
Supponendo che i registri siano 8 e la lunghezza totale sia di 32 bit, e la parola è da 16, quanti spazi rimangono per descrivere l’operazione?
Sapendo che la parola è di 16 bit e noi abbiamo a disposizione 32 bit, i rimanenti bit saranno 16. ma, ammesso che volessimo codificare anche i registri (che sono 8), quanti bit ci occorrerebbero? Ci servirebbero 3 cifre differenti poiché 2 alla terza da 8 come risultato.
Lo stesso discorso varrebbe se dovessimo codificare 100 cifre: siccome contiamo in base due (sistema binario), per codificare 100 cifre faremo 2 elevato alla 10.
Quindi, avendo 2 cifre e 3 posizioni, i numeri che si possono codificare sono 8 perché il risultato di 2 elevato alla 3 è 8. 3 posizioni sono 3 bit. 16 – 3 = 13. i bit che ci rimangono sono 13.
Il passaggio successivo codificare “ sposta”, “ somma”… in 13 bit. Non possiamo codificare 3 numeri, ma se ne codificassimo due ce la potremo fare? Cioè se SPOSTA lo chiamassimo SP e SOMMA lo chiamassimo SO?
Per codificare una cifra occorrono 8 bit. Questo sistema di codifica dei caratteri si chiama codice Asci. Se dobbiamo codificare due cifre, e per una sola di queste occorrono 8 bit, ne codificheremo 1 e mezzo?
Dentro 32 bit ho quindi:
- un indirizzo
- un registro
- un codice operativo (che dice alla macchina cosa fare)
In realtà, per fare in modo che si riesca a codificare tutte e due queste cifre, bisogna ordinare le operazioni fin’ora elencate e ordinarle in sequenza; queste operazioni prenderanno il nome di 0.0 (operazione di “alt”), 0.1… le possiamo ordinare lessicograficamente, quindi come se appartenessero ad un dizionario. Perciò, le diverse operazioni che si possono codificare in 13 bit sono 2 elevato alla 13 (molte di più di 13).
Il codice operativo è un numero che non ha il significato di un numero di quell’operazione, ma è un numero che potrebbe rappresentare l’ordine di una lista che potremmo mettere da parte, per comprendere, successivamente, ciò che abbiamo scritto.
Abbiamo conosciuto un linguaggio, e abbiamo fatto in modo che fosse contenuto in 32 bit. E questo linguaggio ha due sintassi: una comprensibile e leggibile da parte degli utenti (umani) e l’altra leggibile da parte della macchina.
Sarà il codice operativo che dirà alla macchina cosa deve fare.
Dato questo linguaggio, una delle cose che possiamo farci è tradurre gli algoritmi. L’algoritmo tradotto nel linguaggio della macchina, non è altro che un programma.
Quanti programmi ci sono a fronte di un algoritmo specifico?
Saranno tanti quanti i diversi linguaggi di macchine. Se vogliamo comunicare con una macchina, dovremo programmarla. Programmare consiste nello scrivere l’algoritmo per una specifica macchina, che ha uno specifico linguaggio.
Ovviamente qualsiasi linguaggio, di qualsiasi macchina, ha la caratteristica di non essere ambiguo. Perciò l’operazione di programmazione è una semplice operazione di traduzione in un linguaggio che non deve essere ambiguo.
Naturalmente si tratta di un linguaggio ristretto. Perciò, se un linguaggio di una macchina non prevede lo svolgimento di una determinata operazione che in quel momento ci serve svolgere, dovremo usare una sottoparte di programma.
Se vogliamo svolgere una divisione tra due numeri interi, usiamo l’algoritmo (non è ancora il programma). Dati due numeri, svolgeremo l’operazione tramite l’algoritmo, che poi bisognerà tradurre in un programma.
Ciò che vogliamo fare è spostare ciò che è contenuto nel Registro di memoria A in AX, e poi spostare ciò che è contenuto nel registro di memoria B in BX. Questi dati possono essere svolti dall’ALU solo quando si trovano nei registri. I contenuti di A e B li abbiamo messi in AX e BX perché devono entrare nella CPU.
A è maggiore o minore di B? Se è maggiore bisognerà fare qualche cosa, se è minore di B bisognerà fare qualcos’altro. Questo qualche cosa o qualche cos’altro, consiste nel saltare da una posizione o saltare a un’altra posizione.
Comparare AX e BX, significa sottrarli. Se la comparazione è uguale a 0, bisogna passare nella posizione “ allora”. Se non è uguale a 0, l’operazione dovrà continuare.
Data una macchina, è formata da una sequenza di istruzioni. Istruzioni che chiamiamo “ linguaggio macchina” (parlando della macchina fisica).
Non tutte le macchine hanno lo stesso linguaggio, al contrario, ogni macchina ha un suo proprio linguaggio che sta a differenti astrazioni.
Se ad una macchina specifica si vuole far eseguire un’istruzione, bisogna che la si comunichi nell’unico linguaggio che può comprendere. Se noi usiamo un altro linguaggio perché non siamo a conoscenza di quello usato dalla macchina, la macchina non funzionerà mai.
Le macchine possono essere fisiche, e cioè immediatamente realizzate attraverso dispositivi fisici e il loro linguaggio viene detto linguaggio-macchina. Mentre esistono anche le macchine virtuali che non esistono fisicamente, ma anch’esse hanno un linguaggio specifico.
I linguaggi di queste macchine sono completamente definiti. Anche nelle lingue usate dagli umani, vi sono lingue completamente definite, ma poco usate, come l’esperanto ad esempio.
Il linguaggio macchina non consiste né nell’insieme degli 0 e 1 del computer, né nel vedere come è la struttura di un cellulare quando ci cade, ma è la differenza di potenziale contenuta nei transistor e cioè quanta elettricità è presente, in un determinato momento, in un transistor.
I transistor sono elementi bistabili, o elementi, piccoli e unitari che possono assumere due stati. Il linguaggio macchina è fatto dalla differenza di potenziale dei transistor. Anche l’elemento fisico che caratterizza i nostri computer è un transistor, perché ha quindi due stati.
L’algoritmo che è stato convertito, e che quindi è diventato un programma, deve andare a finire nella memoria. A eseguirlo sarà l’algoritmo vitale o sistema operativo. Ogni istruzione dovrà essere caricata, localizzata, decodificata ed eseguita, fin quando non si incontrerà l’istruzione “ alt”.
A sinistra, in figura, c’è la memoria, mentre a destra ci sono la maggior parte dei registri della CPU. I dati che ci interessano, si trovano nelle celle di memoria 200 e 202. il risultato lo vogliamo ottenere nella cella di memoria 204.
Siccome vogliamo eseguire questo programma, l’indicazione di dove la prima istruzione del programma si trova, dovrà essere molto precisa. Così, nel Program Counter verrà caricato l’indirizzo della prima istruzione (100). Poi, quest’istruzione verrà messa nel MAR, infatti, l’unico modo che si ha se si vuole comunicare con la memoria, è usare il MBR o il MAR.
Una volta caricata anche l’istruzione “101”, si avrà terminato l’operazione e, nell’Instruction Register si troverà ciò di cui si aveva bisogno.
In realtà l’operazione è svolta per metà (carica e localizza).
Una volta caricato in memoria un programma, lo si è modificato adattandolo alla memoria e precisamente a quella parte di memoria dove il programma è stato scritto. Ciò che va spostato (in questo caso 202 e 200) dipende da dove il programma andrà posto all’interno della memoria.
La Macchina di Von Neumann mischia dati ed algoritmi, carica decodifica ed esegue.
La Macchina di Von Neumann, è una macchina virtuale che, quindi, in realtà non esiste. Ogni volta che un utente usa una qualsiasi macchina, ne deve conoscere le regole e il linguaggio, quindi è l’utente che si adegua alla macchina.
Benché la Macchina di Von Neumann non esista, tutti gli elementi tecnologici, in grado di fare calcoli, sono Macchine di Von Neumann (computer, cellulare, ...)